本文已收录到《jsmini系列文章》
划重点,这是一道面试必考题,我就问过很多面试者这个问题,✧(≖ ◡ ≖✿)嘿嘿
今天我们将探讨如何处理 JavaScript 中的一个常见问题:深层数据访问。
JavaScript 中常用的引用数据结构是数组和对象,数组表示有序数据,对象表示无序数据,使用对象和数组可以组合出任何数据结构,如对象嵌套对象可以表示树形结构等。示例代码如下:
const tree = {
left: { a: 1 },
right: { b: 2 },
};
当嵌套层级很深时,读/写深层数据并不简单,这篇文章将一步步指导你构建一个名为 anypath 的库,介绍如何读/写深层数据中的数据。
背景知识
下面先来了解读取深层数据问题,上面的例子如果想读取tree.left中的a属性,一般会写如下的代码
const tree = {
left: { a: 1 },
right: { b: 2 },
};
console.log(tree.left.a);
这么写逻辑上正确,但是容错性很差,为什么这样说呢,因为 JavaScript 是动态类型的,在编译阶段无法发现类型的问题,如果数据是完全可控的,比如上面的tree中的数据,但更多的情况下数据可能来源于接口数据,用户输入数据等,思考下如果tree上的left不存在会发生什么
const tree = {
right: { b: 2 },
};
console.log(tree.left.a); // Uncaught TypeError: Cannot read properties of undefined
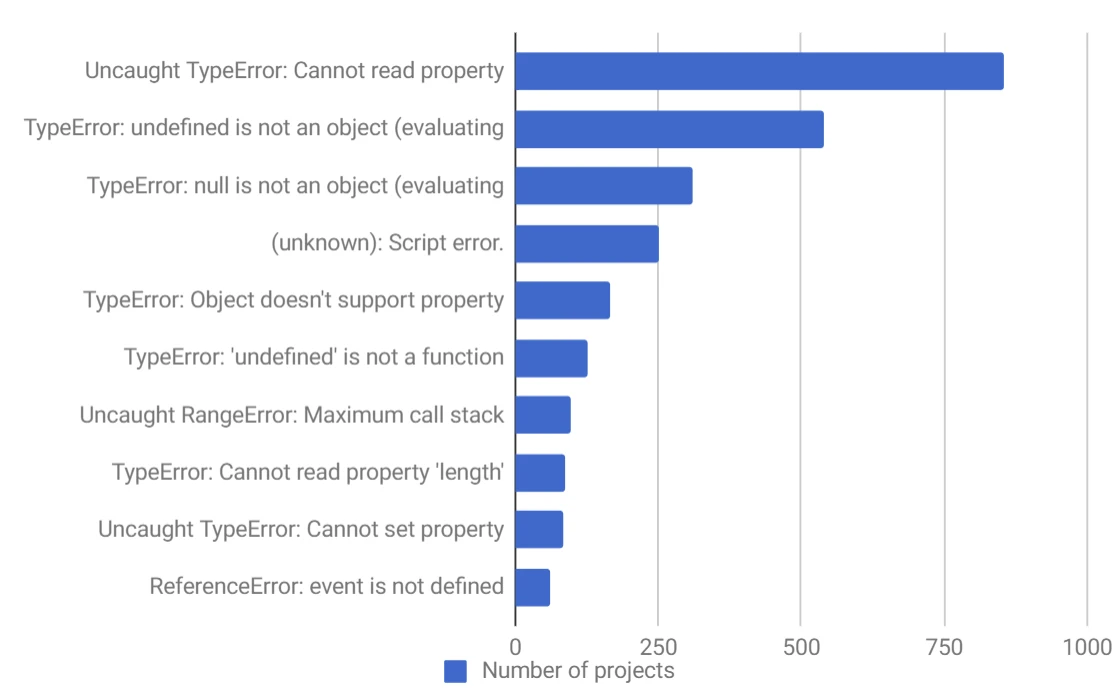
程序出错了,因为left的值是undefined,根据网络上的数据,从undefined和null上读取属性,位于 10 个最常见的 JavaScript 错误的第一位
应对这种报错,之前常见的写法是借助或运算符的短路算法,在读取之前先判断父元素是存在的
const tree = {
right: { b: 2 },
};
console.log(tree.left || tree.left.a); // 如果left返回undefined,则直接返回undefined,不执行后面的逻辑
这种写法对于层级较少时尚可,当层级较深时,每一层都可能为空时,就会让判空逻辑变得很长
tree.left || tree.left.left || tree.left.left.left || tree.left.left.left.a; // 每一层都要判空
更好的做法是为这个问题写一个库,社区里已经有不错的库可以直接使用,在本节后面的内容中会写一个,这里继续介绍其他方法
下面看下语言层面的解决方案,TypeScript 是一个 JavaScript 的方言,在 TypeScript 中可以给数据添加类型约束,这样如果数据可能为空的场景会在编译阶段给出提示,而不是运行时才会报错,不过需要是开启严格模式--strictNullChecks才可以,下面是 TypeScript 版本代码
interface Tree {
left?: { a: number }; // left是可选属性
right: { b: number };
}
const tree: Tree = {
right: { b: 2 },
};
console.log(tree.left.a); // 编译时报差,提示left可能为空
在 TypeScript 中对于可能为空的数据,不需要使用或运算符,可以使用可选操作符?
console.log(tree.left?.a); // 不报错,返回undefined
但并不是所有项目都是用 TypeScript,由于这个问题实在太普遍,ECMAScript 2020 引入了可选链操作符(Optional Chaining),从语言层面带来了原生支持,也是使用?操作符
const tree = {
right: { b: 2 },
};
console.log(tree.left?.a); // 不会报错
不过需要现代浏览器环境才能原生支持,如果有兼容性问题,可以使用 Babel 转换代码,下面是 Babel 转换完的代码,可以看到组合了或操作符和三目运算符
var _tree$left;
var tree = {
right: {
b: 2,
},
};
(_tree$left = tree.left) === null || _tree$left === void 0
? void 0
: _tree$left.a;
对于读取深层数据的问题,建议使用语言原生的解决方案
下面介绍写深层数据问题,如果父对象不存在,直接写的话会报错
const tree = {
right: { b: 2 },
};
tree.left.a = 1; // Uncaught TypeError: Cannot set properties of undefined (setting 'a')
语言层面未提供这个问题的能力,使用上面的可选链操作符是不行的,原因是表达式的左边的值是不能存在可选链的
const tree = {
right: {b: 2}
}
tree.left?.a = 1 // Uncaught SyntaxError: Invalid left-hand side in assignment
一般比较简单的思路,是把控制操作符提取到上层的判断中,即便层级变多也不会报错了
const tree = {
right: { b: 2 },
};
// 赋值之前先判断父路径存在,结合可选链使用
if (tree.left?.left) {
tree.left.left.a = 1;
}
但这种方法有个严重缺陷,如果父路径不存在时是不会进行赋值操作的,判断里的逻辑不会执行,对于希望赋值能够成功,给不存在的层级自动创建默认值的场景,是不支持的,下面我们会抽象一个库,解决这个问题。
搭建脚手架
首先给我们的库起一个名字,这里我们就叫他 anypath 吧,意思是可以读写任意路径的数据。接下来需要搭建一个写库的框架。
推荐使用我的 jslib-base 工具,它提供了一整套完善的库开发工具,包括 TypeScript、Babel、ESLint、Prettier 等。下面是使用 jslib-base 工具搭建项目的步骤:
$ npx @js-lib/cli new anypath
# Interactive queries, input project info
$ cd anypath
$ npm i
完成后你会得到如下的目录,直接在 src 目录写代码即可。
.
├── demo Usage demo
├── dist Compiled out code
├── doc Project documents
├── src Source code directory
├── test Unit tests
├── CHANGELOG.md Change log
└── TODO.md To-do features
代码实现
写深层数据的函数的设计如下,第一个参数是数据根节点,第二个参数是赋值路径,路径是一个字符串,使用.号分隔表示每一层容器的名字,第三个参数是要设置的值,使用方法如下
export function setany(obj, key, val) {}
const tree = {
right: { b: 2 },
};
setany(tree, 'left.a', 1); // 等价于 tree.left.a = 1
下面是第一版代码,整体思路比较简单,首先解析 key,然后遍历判断每一层是否存在,不存在则自动创建空对象作为容器
export function setany(obj, key, val) {
const keys = key.split('.');
const root = keys.slice(0, -1).reduce((parent, subkey) => {
return (parent[subkey] = parent[subkey] ? parent[subkey] : {}); // 不存在则自动创建空对象
}, obj);
root[keys[keys.length - 1]] = val;
}
上面的代码存在一个问题,如果数据层级中存在数组的话,会被错误的初始化为对象,也就是说不支持容器是数组类型
const tree = {};
setany(tree, 'arr.1', 1); // 希望得到 { arr: [1] } 实际得到的是 { arr { 1: 1 } }
如何能让键区分出来对象和数组呢?可以简单的给数组类型的键后面添加[]后缀
const tree = {};
setany(tree, 'arr[].1', 1); // 可以得到 { arr: [1] }
下面是改造后的代码,能够识别键是对象还是数组,从而自动创建不同类型的默认值
function parseKey(key) {
return key.replace('[]', '');
}
export function setany(obj, key, val) {
const keys = key.split('.');
const root = keys.slice(0, -1).reduce((parent, subkey) => {
const realkey = parseKey(subkey);
// a.b[].c b是数组
return (parent[realkey] = parent[realkey]
? parent[realkey]
: subkey.includes('[]')
? []
: {});
}, obj);
root[keys[keys.length - 1]] = val;
}
目前已经支持对象和数组作为容器,这能满足大部分场景,但 ECMAScript 2015 带来了原生的 Map 和 Set,弥补了 JavaScript 原有对象数组类型的缺陷,下面简单介绍下 Map 和 Set 的功能
Map 类型和对象类型功能一样,也是表示无序键值对,JavaScript 中的对象类型实际上承载了数据结构中的键值对和面向对象中的对象实例两个功能,在作为数据结构中的键值对这一方面存在一些缺点,比较明显的有,键的类型只能是字符串和空对象可以读取到原型上的属性
const obj = {};
obj['str'] = '1'; // 键值只能是字符串
// 非字符串值都要转换为字符串值,下面的没区别
obj[1];
obj['1'];
obj[new Number(1)];
obj.toString; // 空对象,也能够读取到原型上的值
Map 的键类型可以是任意类型,Map 的键是使用同值零算法确认是否相同,同值零认为 NaN 和 NaN 是相同的,认为+0 和-0 是相同的
new Map([
[NaN, 1],
[NaN, 2],
]); // Map(1) {NaN => 2}
new Map([
[0, 1],
[-0, 2],
]); // Map(1) {0 => 2}
下面是 Map 和对象的使用方法的简单对比
// 新建
const map = new Map([['a', 1]])
const obj = { a: 1 }
// 读取属性
map.get('a')
obj.a
// 设置属性
map.set('b', 2)
obj.b = 2
Set 可以理解为自带去重功能的数组,Set 中的数据是有序的,遍历时按照插入的顺序输出,Set 和 Array 的区别是,重复向 Set 中放入同一个值,最终只会存在一份
const arr = [];
arr.push(1);
arr.push(1);
console.log(arr); // [1, 1]
const set = new Set();
set.add(1);
set.add(1); // Set(1) {1}
Set 中的值总是唯一的,判断两个元素是否相等,使用的是同值零算法,在前面已经介绍过这个算法,同值零认为 NaN 和 NaN 是相同的,认为+0 和-0 是相同的
new Set([+0, -0]); // Set(1) {0}
new Set([NaN, NaN]); // Set(1) {NaN}
利用 Set 的唯一值特性,可以使用 Set 完成数组的去重
const arr = [1, 1, 2, 3];
const uniqArr = [...new Set(arr)]; // [1, 2, 3]
Set.prototype属性指向Object.prototype,并不是Array.prorotype,可以使用instanceof验证下
const set = new Set();
set instanceof Set; // true
set instanceof Array; // false
set instanceof Object; // true
所以 Set 上面并没有数组上面的方法,其有一套自己接口和数组完全不同,下面是简单对比
let arr = [];
let set = new Set();
// 添加元素
arr.push(1);
set.add(1);
// 获取长度
arr.length;
set.size;
// 删除元素
set.delete(1);
// 数组没有delete,只能filter代替
// 如果知道key的话,也可以使用splice,注意还修改原数组
// 如果删除开头和结尾的元素的话,可以使用pop和shift
arr = arr.filter((v) => v !== 1);
那么我们的库如何支持新的数据类型作为容器呢?参考上面的思路,可以继续扩展,比如扩展键值增加:,冒号后面代表类型
setany(tree, 'arr:Array.0.m:Map.a.', 1);
// 上面设置后,会生成下面的数据结构
const tree = {
arr: [new Map(['a', 1])],
};
写深层数据问题已经解决,前面提到读深层数据建议使用 JavaScript 原生的可选链操作符,但如果使用了深层写数据的业务,可能希望能够有对应的读操作,下面完成通过一套key提供完整读和写的功能
读数据的思路比较简单,和写的思路类似,但却不用创建数据,只需要区分下数据类型,使用不同的 api 读取即可,这里只提供了对象和数组的版本,对象和数组的读操作可以统一使用[]语法
export function getany(obj, key) {
return key.split('.').reduce((prev, subkey) => {
// a.b[].c b是数组
return prev == null ? prev : prev[parseKey(subkey)];
}, obj);
}
总结
在这篇文章中,我们深入探讨了在 JavaScript 中处理深层数据访问的常见问题。我们首先了解了读取和写入深层数据的挑战,以及传统和现代解决方案,包括可选链操作符和 TypeScript 的可选属性。在解决写入深层数据时,我们构建了一个名为anypath的库,能够智能地识别并处理不同类型的容器(如对象和数组),并提供了简单易用的 API。
通过搭建脚手架并一步步实现setany函数,我们不仅解决了深层数据写入的问题,还为未来的扩展奠定了基础,比如支持 Map 和 Set 等高级数据结构。
希望这篇文章能帮助你更好地理解和处理 JavaScript 中的深层数据访问问题。你可以在项目中直接使用anypath库,源代码地址如下:https://github.com/jsmini/anypath
原文网址:http://yanhaijing.com/javascript/2024/06/08/deep-data/


