最近经验要迁移到https,需要排查页面中需要用到的全部资源,我用nodejs+phantomjs做了一个自动收集页面资源的程序,本文分享下自己的一点经验,注意文章结尾有干货
如果全文只能说一句话,那我想说的是,“一定要打破自身局限性,要走出舒适区,身为前端不能被前端局限住视野”,前端虽美,可不要贪杯哦

调研
我最先想到的方案就是手动收集依赖,但这种方式明显不可取,但在一番曲折之后我发现了HAR这种神奇的东西,一句话概括,HAR是一种数据格式,对人家还有专门的组织定义规范了,起作用是定义网络请求的数据规范,以便在不同工具中共享数据
感兴趣的同学可以自己导出数据看下格式,上面从chrome面板导出数据,让后放到HAR Viewer工具就可以还原了,似不似很神奇,O(∩_∩)O哈哈~
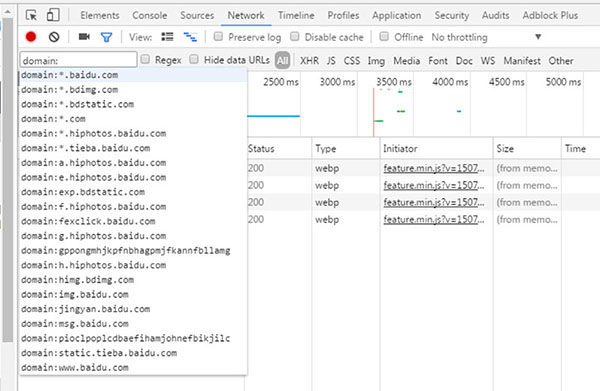
小技巧:如果想收集一个页面依赖了哪些域名,可以这样操作
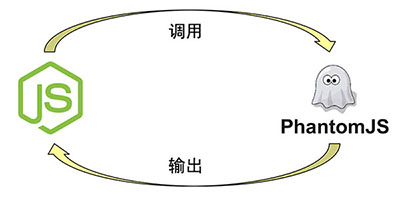
目标是自动化,我打算用node来写逻辑,一番调研后发现phantomjs是一个无头浏览器,可以被node调用,真个程序的架构就清晰了,涉及node,phantomjs和HAR
理想很丰满,现实很骨感,我其实没用过phantomjs,也没写过node,o(╯□╰)o
phantomjs
phantomjs是一个没有界面的,可通过JavaScript api编程的Webkit,快速并且原生支持多种web标准:DOM处理,CSS选择器,JSON,Canvas和SVG,这是官网对phantomjs的介绍
phantomjs的整体架构如下,我们可以调用phantomjs暴漏的api,从而实现自己想要的功能
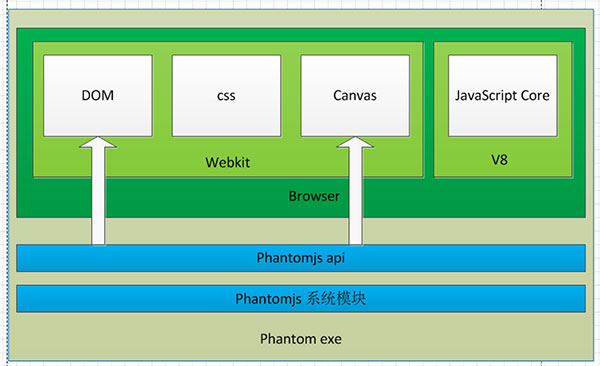
phantomjs的主要功能有4大块,而网络监控正是我需要的
- headless website testing 无界面网站测试
- screen capture 页面截图
- page automation 页面自动化测试
- network monitoring 网络监控
网络上关于phantom的教程要么停留在v1,从v2开始phantom有了独立的可执行程序,在windows下就是exe,需要单独安装,可以在这里下载对应的安装程序,安装好后还需添加到path路径,在node中也会调用这个可执行程序
在命令行输入phantomjs -v,验证是否安装成功
新建一个test.js
var page = require('webpage').create();
page.open('http://example.com', function(status) {
console.log("Status: " + status);
if(status === "success") {
page.render('example.png');
}
phantom.exit();
});
然后用phantom运行这个js,就可以得到对应页面的截图,是不是很简单,注意这个test.js是用phantom运行的
phantomjs ./test.js
nodejs
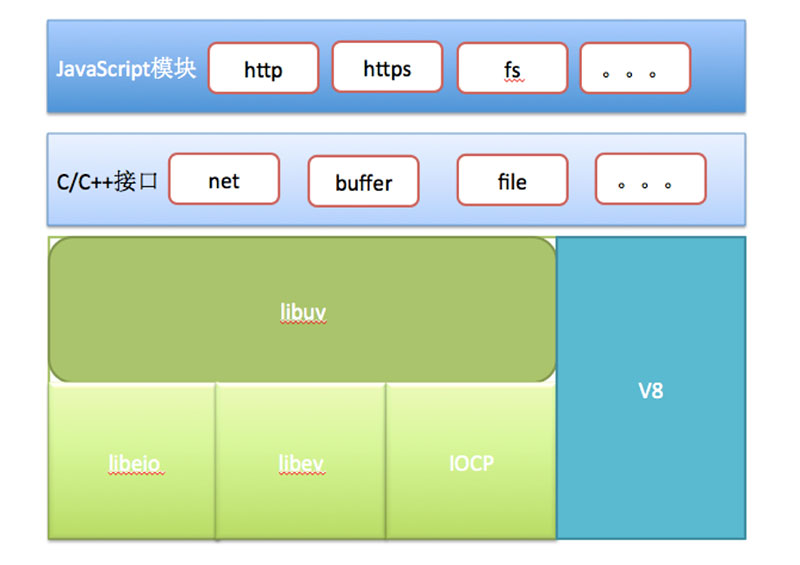
Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境,其架构如下
作为一个没怎么用过node的前端老司机,我给前端的建议是不要怕,node其实并不难,或者说用node完成自己想做的事情并不难
学习node必须先了解这四个基本概念,commonjs、package、npm、package.json
由于js本身缺少模块的功能(es6已经有了原生支持),为解决这个问题,社区创造了commonjs,node中的模块都是commonjs模块,一个模块可以暴漏接口供其他模块使用,也可以引用其他模块暴漏的接口
var q = require('q'); // 依赖模块q
exoprts.a = q; // 暴漏给其他模块使用
有时候我们会想吧几个js文件给别人,让别人使用,这是package的概念,package是一堆功能类似的模块的集合,每个package的根目录都有一个package.json文件,用来记录一些自己的信息,比如名字,版本号等
我们自己的node项目也会有一个package.json文件,主要是用来记录依赖了哪些第三方包
node的开源包一般都在npm这个社区上,npm同时可以安装包的一个命令行工具,比如我们再npm网站上找到了bootstrap这个包,就可以在命令行用npm安装这个包,安装好后,可以将这个依赖写到package.json,方便以后安装
npm install bootstrap
node作为一个有了对系统完整操作的功能,所有有众多内置模块,带星号的是我用到的模块,看到这么多不要慌,你可能只会用到20%
- Buffer 二进制文件相关
- *Child Processes 处理子进程的模块
- *Console 控制台输出
- Events 事件系统
- *File System 文件系统
- *Globals 全局变量
- HTTP http请求相关
- Utilites 内置工具函数
- *URI URL相关操作
- Stream 文件流相关
- Query String
- *Process 当前进程相关
- *Path 文件路径相关
- Modules 模块相关
技术细节
为了可扩展性,我将整个系统设计成四个部分,配置系统,获取HAR系统,解析系统,可视化系统
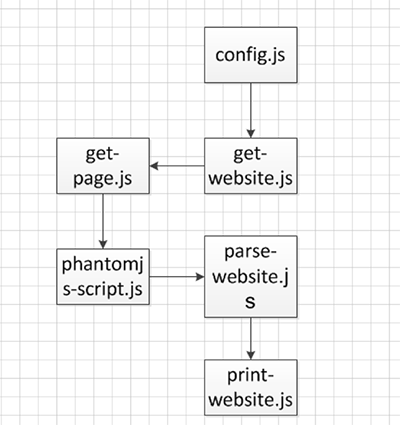
config.js是配置文件,我将配置做成网站加页面的维度,这样就可以统计多个网站的多个页面了
get-website.js读取config.js,然后解析成网站和对应的页面
get-page.js里是获取每个页面网络数据,因为要执行子进程,所以要用到execFile
parse-website.js负责将数据按照页面,网站收集,分类,整理
print-website.js负责将数据打印输出,涉及文件读写
整个程序用到了child_process,调用phantom子进程
childProcess.execFile(binPath, childArgs, {maxBuffer: 1000*1024}, function(err, stdout, stderr) {
if (err) {
reject(stdout || stderr || err);
return;
}
// handle results
resolve(stdout);
});
process获取当前进程的信息,如获取当前程序的路径,环境变量
process.cwd()
path路径相关操作,如拼接读写文件的路径
var path = require('path')
path.join(__dirname, 'phantomjs-script.js')
fs读写文件,如将最终数据写入文件
fs.writeFile(filepath, content, function (err) {
if (err) {
reject(err);
return;
}
resolve(name);
});
总结
整个系统可以实现对配置文件中的页面依赖的资源进行收集整理和分析,终于把手工的工作变成了自动的,作为一个程序员一定要有自动化的意识,重复的工作让机器来做
这种脚本类型的任务,node的异步会让程序更复杂,o(╯□╰)o
如果然我推荐一篇学习nodejs的文章的话,那我推荐《七天学会nodejs》,如果让我推荐一本书的话,我推荐《nodejs实战》
原文网址:http://yanhaijing.com/nodejs/2016/11/11/some-practice-of-nodejs/





